The runtime authority for enterprise AI.
Control what AI systems are allowed to do in production. Enforce policy before execution and automatically generate audit-ready evidence.
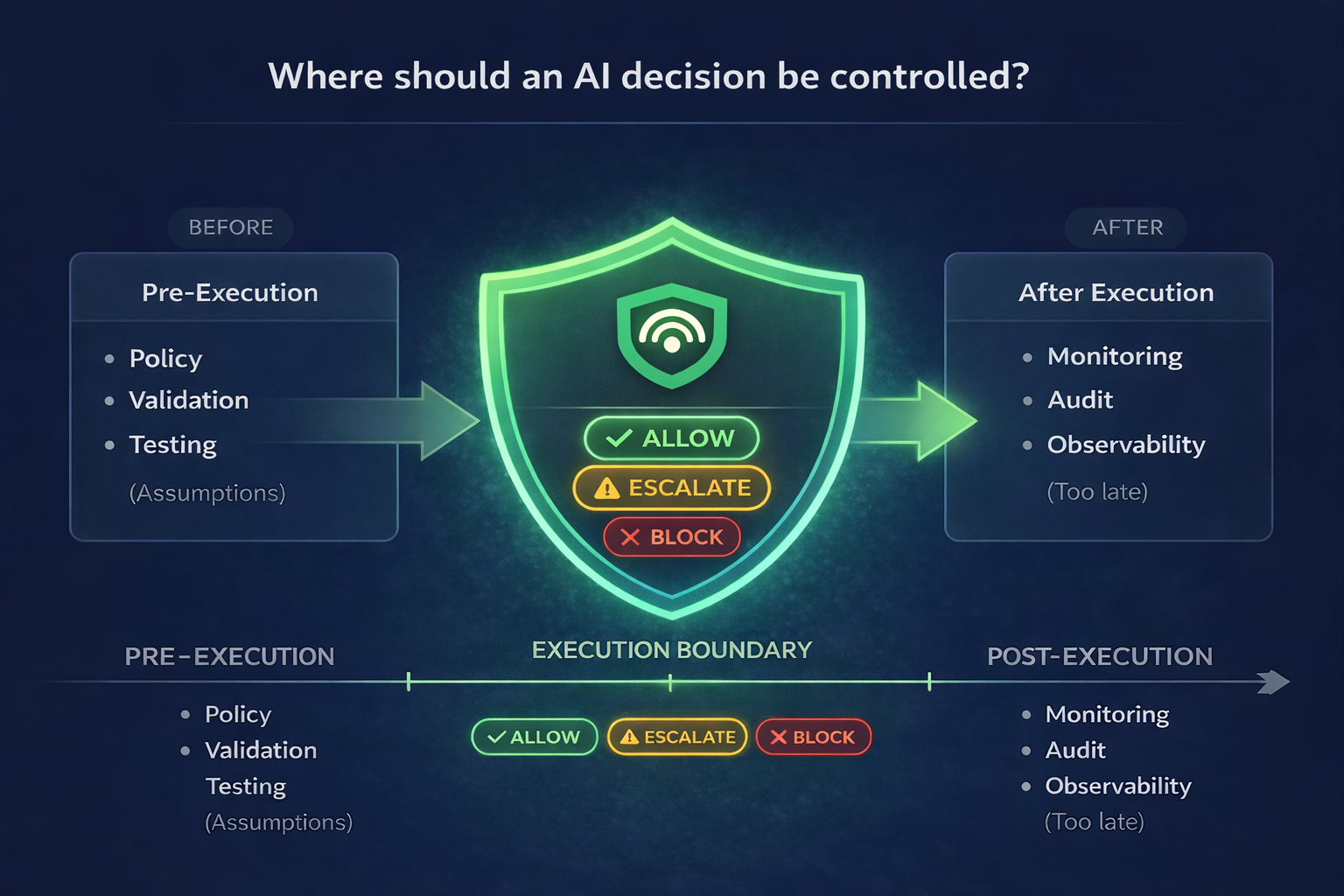
Between AI decisions and business impact.
Every enterprise deploying AI needs a runtime authority. DriftGard is that authority.
These are not chatbot problems. They are business-impact problems.
When agents can call tools, access regulated data, approve workflows, and trigger downstream systems, a bad response can become a real action.
AI approved a high-value action
A support agent called a payment or refund tool without an amount limit, role check, or approval boundary.
AI emailed confidential customer data
A prompt injection or unsafe tool argument caused PII, secrets, or regulated customer context to leave the system.
Regulator asks why the AI approved it
Weeks later, the team cannot prove which policy was active, why the decision passed, or whether a control fired.
Most tools check what AI says.
Prompt filters, evals, and dashboards help teams understand output risk. They often answer: what did the AI say?
DriftGard controls what AI does.
DriftGard evaluates decisions and actions in the runtime path. It answers: was it allowed, why, and can we prove it?
Observe, control, and prove every AI decision.
Start with low-friction evaluation, then move selected production workflows into Inline Enforcement when teams are ready for DriftGard to sit in the model-call path.
Audit existing AI apps without changing provider traffic.
Your application calls the model, then sends prompt, response, model, tool, and agent context to DriftGard for policy evaluation, evidence, reporting, and live activity.
Put DriftGard directly between your app and the LLM.
Use the OpenAI-compatible /gateway/v1/chat/completions endpoint or SDK gateway methods to enforce policy before and after provider execution across OpenAI-compatible, Azure OpenAI, and Anthropic providers.
Four controls that matter in production.
Everything else in DriftGard supports these outcomes: enforce, govern, investigate, and prove.
Runtime enforcement
Evaluate existing AI traffic or route model calls through DriftGard's Inline Enforcement gateway. Allow, block, redact, fallback, fail over across providers, or route to live approval.
Model and tool governance
Approve model IDs, validate tool access, enforce agent and user context, and inspect risky parameters.
AI operations visibility
Track prompt injection, policy evasion, DLP, risky tool usage, agent behavior, cost, tokens, and latency.
Compliance evidence
Generate audit records, reports, provenance, integrity checks, and framework-mapped evidence from real AI traffic.
Govern the knowledge your AI uses, not just the answer it gives.
DriftGard adds policy, trust, retrieval audit, and replay to enterprise RAG workflows so teams can prove which documents shaped a model response.
Source-aware retrieval for regulated AI.
Connect upload, S3, or Confluence knowledge sources, attach source trust metadata, suppress archived or expired content, and inject approved context through DriftGard's AI Gateway.
Build RAG workflows your risk team can inspect.
Use DriftGard to govern prompts, responses, tools, models, and the knowledge context that feeds AI decisions.
A policy decision your application can act on.
DriftGard returns structured decisions that product teams can use for fallback messages, approvals, workflow routing, UI warnings, or audit workflows.
{
"decision": "block",
"decision_source": "policy",
"risk_score": 22.4,
"model_id": "gpt-4o-mini",
"violations": [
{
"clause_id": "ADV-IGNORE-INSTRUCTIONS",
"severity": "high"
}
],
"decision_metadata": {
"review_required": true,
"workflow": "security_triage"
},
"evidence": "stored"
}
Customer support AI in fintech.
Same workflow, different outcome. One creates a compliance incident. The other blocks the risk and creates evidence.
Without DriftGard
With DriftGard
Enforcement stops the incident. Evidence proves it.
DriftGard is designed for teams that must show what happened, why it happened, who approved it, and which policy was active at the time.
| Capability | Open-source guardrails | Runtime security tools | DriftGard |
|---|---|---|---|
| Policy enforcement | Yes | Yes | Yes |
| Tool call validation | Yes | Yes | Yes |
| Per-tool identity rules | Limited | Partial | Yes |
| Approved model governance | No | Partial | Yes |
| Decision metadata for workflows | No | Partial | Yes |
| Local evaluation mode | No | No | Yes |
| Tamper-evident audit trail | No | No | Yes |
| Compliance reports and evidence | No | No | Yes |
| Board-ready reporting | No | No | Yes |
| Agent, cost, and latency rollups | No | Partial | Yes |
| Backtesting, synthetic, and batch testing | Partial | Partial | Yes |
| Time to audit evidence | Weeks | Weeks | Minutes |
Start with proof. Scale into production control.
DriftGard is usually adopted through a scoped pilot, then expanded into runtime governance once the policies, workflow, and evidence model are validated.
Design partner
Validate DriftGard against one high-risk AI workflow with hands-on support.
- Policy and risk review
- Runtime evaluation setup
- Control Pack configuration
- Evidence export
Runtime governance
For teams ready to enforce policies on live AI systems and agents.
- SDK and API evaluation
- Inline Enforcement gateway
- Model and tool governance
- Live activity and security center
- Human review workflows
- Compliance reports
Custom
For larger environments with sovereignty, support, or partner requirements.
- Everything in production
- Local and metadata-only modes
- Advanced testing workflows
- Industry templates
- Dedicated support
Frequently asked questions
Short answers for teams evaluating DriftGard as a runtime governance layer.
Is DriftGard a monitoring tool?
No. DriftGard sits in the runtime path. It decides what AI is allowed to do, blocks violations before they reach users, validates tool calls before execution, and creates evidence that the control was applied.
How does it handle AI agent tool calls?
Tool calls are evaluated against policy using model ID, tool name, parameters, agent identity, user context, jurisdiction, chain depth, cost, and data sensitivity before the action is allowed to proceed.
What happens if DriftGard is unavailable?
The SDK supports circuit breaker behavior and configurable failure modes. Teams can choose fail-open for availability-sensitive paths or fail-closed for high-risk workflows.
Can we run it without sending sensitive content to DriftGard?
Yes. Local evaluation and metadata-only modes let sensitive prompts and responses stay inside your environment while still reporting verdict metadata for dashboards and compliance evidence.
How quickly can we start?
A pilot can start with one high-risk workflow, one control pack, and SDK or API evaluation. Most teams begin in observe mode, then move selected controls into enforcement.
Request a demo or pilot audit
Tell us what AI agents or copilots you are shipping. We will show the control path, integration model, and evidence workflow that fits your environment.
What you will see in the demo
Start in observe mode, profile real AI behavior, generate control policies, then enable runtime enforcement when ready.